JavaScript 混淆安全加固
- 2021.05.17
关于前端代码加密这块,大部分的前端代码都是公开的,没有做加密相关的处理,那么对前端代码进行加密有意义么?
大部分人可能觉得前端代码加密毫无意义,谁会去关注你前端代码写了啥,要去加密的话还要自研算法,不如直接走https认证。
确实通过HTTPS可以解决很多问题,但是它解决的是传输层的问题,传输层之外的事情它管不了。这么一想,是不是有必要通过必要的加密手段来保证我们代码的安全性?
加密的环节
加密的环节有很多种方式,例如:
- 传输加密(对抗链路破解)
- 数据加密(对抗协议破解)
- 代码加密(隐藏算法、反调试...)
具体的途径还有很多,与其说加密还不如说代码混淆,这里仅对常见的场景进行描述。
混淆的原理
那么,代码混淆的具体原理是什么?
其实很简单,就是去除代码中尽可能多的有意义的信息,比如注释、换行、空格、代码负号、变量重命名、属性重命名、无用代码的移除等等。因为代码是公开的,所以其实没有任何一种算法可以完全不被破解,所以,我们只能尽可能增加攻击者阅读代码的成本。
语法树 AST 混淆
在保证代码原本功能性的情况下,我们可以对代码的 AST 按需进行变更,然后将变更后的 AST 再生成一份代码进行输出,达到混淆的目的。我们最常用的 uglify-js 就是这样对代码进行混淆的,当然 uglify-js 的混淆只是主要进行代码压缩,即我们下面讲到的 变量名混淆。
变量名混淆
将变量名混淆成阅读比较难阅读的字符,增加代码阅读难度,上面说的
uglify-js进行的混淆,就是把变量混淆成了短名(主要是为了进行代码压缩),而现在大部分安全方向的混淆,都会将其混淆成类 16 进制变量名,例子如下:
- 混淆前:
const str = "hello";
- 混淆后:
var _0x2b6f = "hello";
WARNING
这里需要注意以下几点:
1. eval语法,eval 函数中可能使用了原来的变量名,如果不对其进行处理,可能会运行报错,如下:
var test = "hello";
eval("console.log(test)");
如果不对 eval 中的 console.log(test) 进行关联的混淆,则会报错。不过,如果 eval 语法超出了静态分析的范畴,比如:
var test = "hello";
var variableName = "test";
eval("console.log(" + variableName + ")");
这种咋办呢,可能要进行遍历 AST 找到其运行结果,然后在进行混淆,不过貌似成本比较高。
2. 全局变量的编码,如果代码是作为 SDK 进行输出的,我们需要保存全局变量名的不变,比如:
<script>
var $ = function(id) {
return document.getElementById(id);
};
</script>
$ 变量是放在全局下的,混淆过后如下:
<script>
var _0x6482fa = function(id) {
return document.getElementById(id);
};
</script>
那么如果依赖这一段代码的模块,调用 $('id') 去获取元素自然会报错,因为这个全局变量已经被混淆了。
常量提取
将 JS 中的常量提取到数组中,调用的时候用数组下标的方式调用,这样的话直接读懂基本不可能了,要么反 AST 处理下,要么一步一步调试,工作量大增。
我们还是使用上述的例子:
- 混淆前:
const str = "hello";
- 混淆后:
var _0x2b6f = ["hello"];
var _0xb7de = function(_0x4c7513) {
var _0x96ade5 = _0x2b6f[_0x4c7513];
return _0x96ade5;
};
var str = _0xb7de(0);
当然,我们可以根据需求,将数组转化为二位数组、三维数组等,只需要在需要用到的地方获取就可以。
常量混淆
将常量进行加密处理,上面的代码中,虽然已经是混淆过后的代码了,但是
hello字符串还是以明文的形式出现在代码中,可以利用 JS 中16 进制编码会直接解码的特性将关键字的Unicode进行了16进制编码。如下:
var _0x9d2b = ["\x68\x65\x6c\x6c\x6f"];
var _0xb7de = function(_0x4c7513) {
_0x4c7513 = _0x4c7513 - 0x0;
var _0x96ade5 = _0x9d2b[_0x4c7513];
return _0x96ade5;
};
var str = _0xb7de("0x0");
TIP
当然,除了 JS 特性自带的 Unicode 自动解析以外,也可以自定义一些加解密算法,比如对常量进行 base64 编码,或者其他的什么 rc4 等等,只需要使用的时候解密就 OK,比如上面的代码用 base64 编码后:
var _0x9d2b = ["aGVsbG8="]; // base64编码后的字符串
var _0xaf421 = function(_0xab132) {
// base64解码函数
var _0x75aed = function(_0x2cf82) {
// TODO: 解码
};
return _0x75aed(_0xab132);
};
var _0xb7de = function(_0x4c7513) {
_0x4c7513 = _0x4c7513 - 0x0;
var _0x96ade5 = _0xaf421(_0x9d2b[_0x4c7513]);
return _0x96ade5;
};
var str = _0xb7de("0x0");
运算混淆
该方式将所有的
逻辑运算符、二元运算符都变成函数,目的也是增加代码阅读难度,让其无法直接通过静态分析得到结果。如下:
- 混淆前:
var i = 1 + 2;
var j = i * 2;
var k = j || i;
- 混淆后:
var _0x62fae = {
_0xeca4f: function(_0x3c412, _0xae362) {
return _0x3c412 + _0xae362;
},
_0xe82ae: function(_0x63aec, _0x678ec) {
return _0x63aec * _0x678ec;
},
_0x2374a: function(_0x32487, _0x3a461) {
return _0x32487 || _0x3a461;
},
};
var i = _0x62fae._0e8ca4f(1, 2);
var j = _0x62fae._0xe82ae(i, 2);
var k = _0x62fae._0x2374a(i, j);
除了将逻辑运算符和二元运算符混淆以外,还可以将函数调用、静态字符串进行类似的混淆,如下所示:
- 混淆前:
var fun1 = function(name) {
console.log("hello, " + name);
};
var fun2 = function(name, age) {
console.log(name + " is " + age + " years old");
};
var name = "Lucy";
fun1(name);
fun2(name, 8);
- 混淆后:
var _0x62fae = {
_0xe82ae: function(_0x63aec, _0x678ec) {
return _0x63aec(_0x678ec);
},
_0xeca4f: function(_0x92352, _0x3c412, _0xae362) {
return _0x92352(_0x3c412, _0xae362);
},
_0x2374a: "Lucy",
_0x5482a: "hello, ",
_0x837ce: " is ",
_0x3226e: " years old",
};
var fun1 = function(name) {
console.log(_0x62fae._0x5482a + name);
};
var fun2 = function(name, age) {
console.log(name + _0x62fae._0x837ce + age + _0x62fae._0x3226e);
};
var name = _0x62fae._0x2374a;
_0x62fae._0xe82ae(fun1, name);
_0x62fae._0xeca4f(fun2, name, 0x8);
上面的例子中,fun1 和 fun2 内的字符串相加也会被混淆走,静态字符串也会被前面提到的字符串提取抽取到数组中。
也就是类似这种:
var _0x62fae = {
_0xeca4f: function(_0x3c412, _0xae362) {
return _0x3c412 + _0xae362;
},
_0xeca4b: function(_0x3c412, _0xae362, _0xae363, _0xae364) {
return _0x3c412 + _0xae362 + _0xae363 + _0xae364;
},
};
然后将fun1中的代码再次进行混淆。
WARNING
需要注意的是,我们每次遇到相同的运算符,需不需要重新生成函数进行替换,这就按个人需求了。
语法丑化
将我们常用的语法混淆成我们不常用的语法,前提是不改变代码的功能。例如
for换成do/while,如下:
for (i = 0; i < n; i++) {
// TODO: do something
}
var i = 0;
do {
if (i >= n) break;
// TODO: do something
i++;
} while (true);
WARNING
当然,采用语法丑化的手段有的时候适得其反,特意丑化的语法可能有时候连我们自己也看不出来这个逻辑到底是啥,指不定还会口吐芬芳问候一下写这代码的人,一看 commit 竟然是自己写的。
动态执行
将静态执行代码添加动态判断,运行时动态决定运算符,干扰静态分析。
var s = 1 + 2;
- 混淆后:
function _0x513fa(_0x534f6, _0x85766) {
return _0x534f6 + _0x85766;
}
function _0x3f632(_0x534f6, _0x534f6) {
return _0x534f6 - _0x534f6;
}
// 动态判定函数
function _0x3fa24() {
return true;
}
var s = _0x3fa24() ? _0x513fa(1, 2) : _0x3f632(1, 2);
流程混淆
对执行流程进行混淆,又称
控制流扁平化。
为什么要做混淆执行流程呢?因为在代码开发的过程中,为了使代码逻辑清晰,便于维护和扩展,会把代码编写的逻辑非常清晰。一段代码从输入,经过各种 if/else 分支,顺序执行之后得到不同的结果,而我们需要将这些执行流程和判定流程进行混淆,让攻击者没那么容易摸清楚我们的执行逻辑。
控制流扁平化又分顺序扁平化、条件扁平化。
顺序扁平化:
顾名思义,将按顺序、自上而下执行的代码,分解成数个分支进行执行,如下代码:
- 混淆前:
(function() {
console.log(1);
console.log(2);
console.log(3);
console.log(4);
console.log(5);
})();
- 混淆后:
(function() {
var flow = "3|4|0|1|2".split("|"),
index = 0;
while (!![]) {
switch (flow[index++]) {
case "0":
console.log(3);
continue;
case "1":
console.log(4);
continue;
case "2":
console.log(5);
continue;
case "3":
console.log(1);
continue;
case "4":
console.log(2);
continue;
}
break;
}
})();
混淆过后的流程图如下:
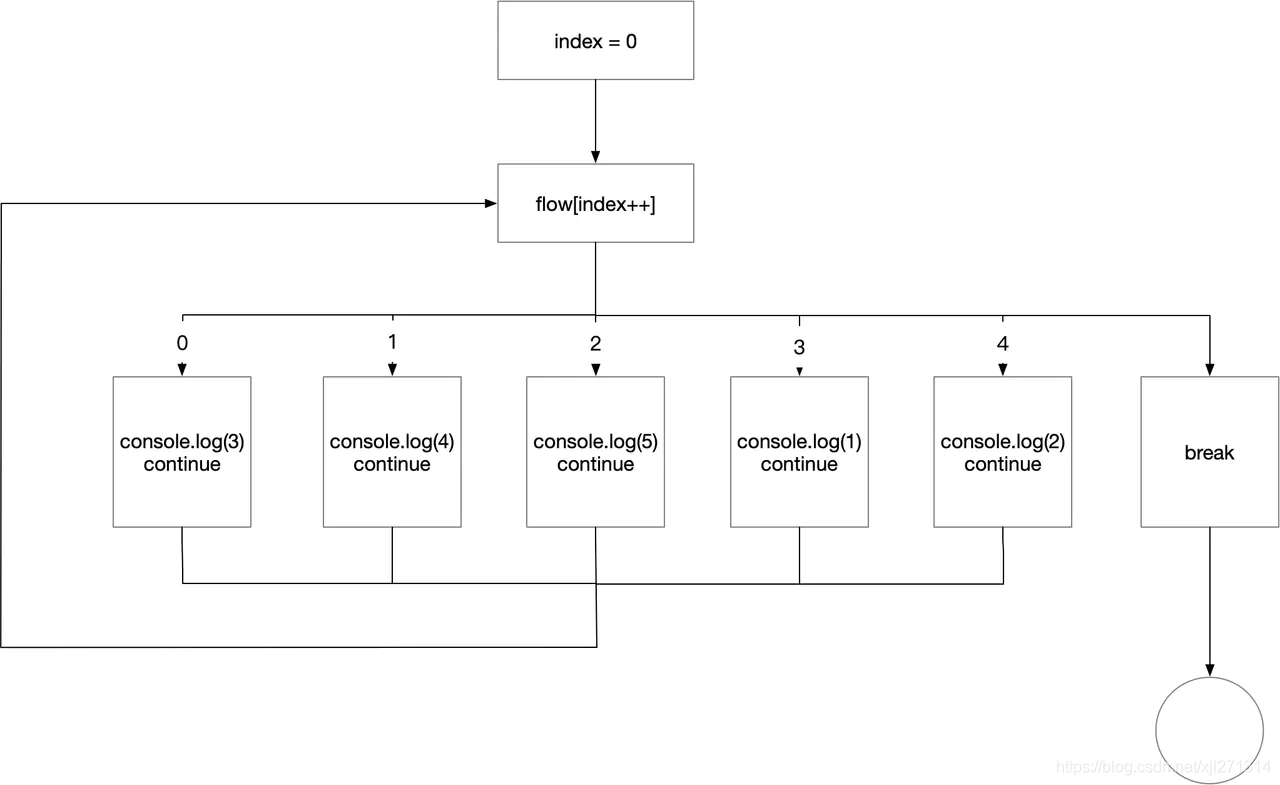
通过该处理方式后流程变得更加扁平化了。
条件扁平化:
条件扁平化的作用是把所有
if/else分支的流程,全部扁平到一个流程中,在流程图中拥有相同的入口和出口。
function modexp(y, x, w, n) {
var R, L;
var k = 0;
var s = 1;
while (k < w) {
if (x[k] == 1) {
R = (s * y) % n;
} else {
R = s;
}
s = (R * R) % n;
L = R;
k++;
}
return L;
}
上述的代码流程图是这样的:
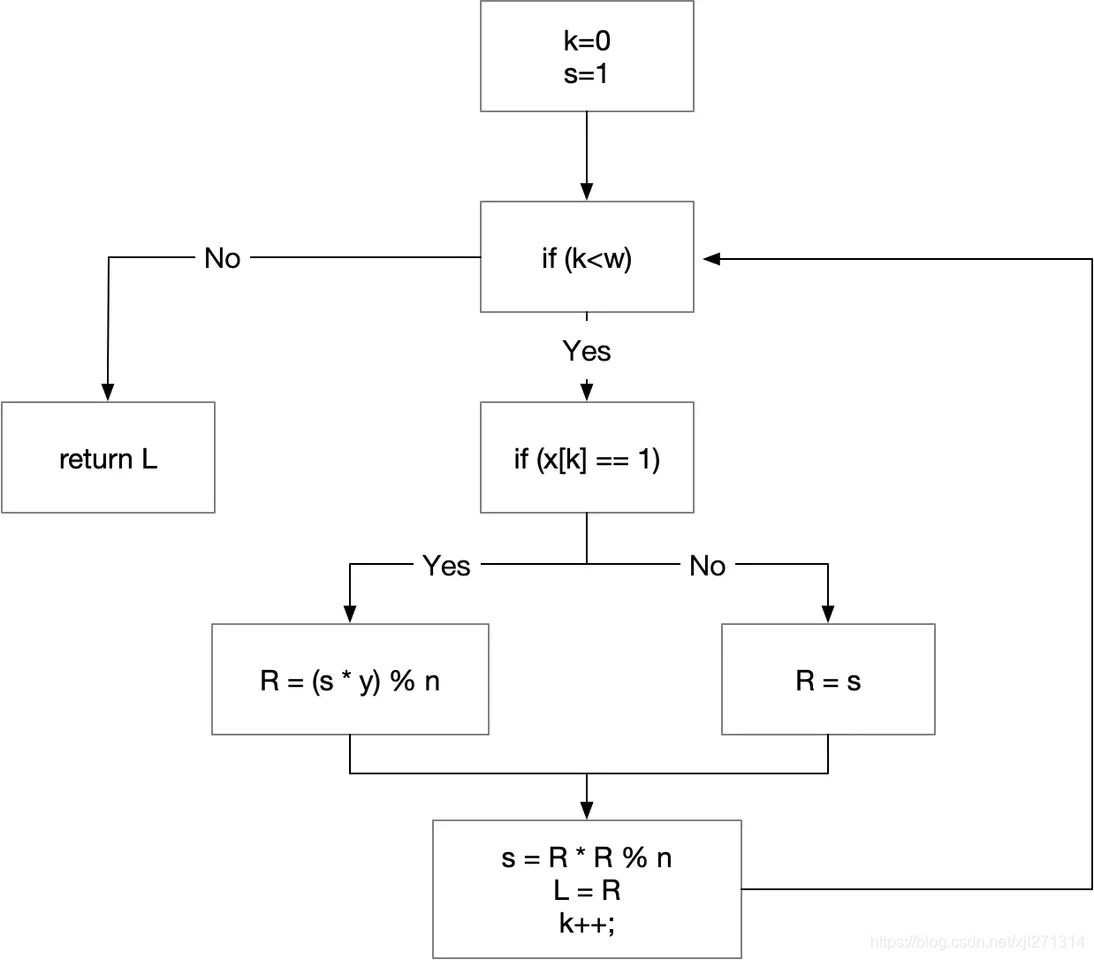
控制流扁平化后代码如下:
function modexp(y, x, w, n) {
var R, L, s, k;
var next = 0;
for (;;) {
switch (next) {
case 0:
k = 0;
s = 1;
next = 1;
break;
case 1:
if (k < w) next = 2;
else next = 6;
break;
case 2:
if (x[k] == 1) next = 3;
else next = 4;
break;
case 3:
R = (s * y) % n;
next = 5;
break;
case 4:
R = s;
next = 5;
break;
case 5:
s = (R * R) % n;
L = R;
k++;
next = 1;
break;
case 6:
return L;
}
}
}
混淆后的流程图如下:
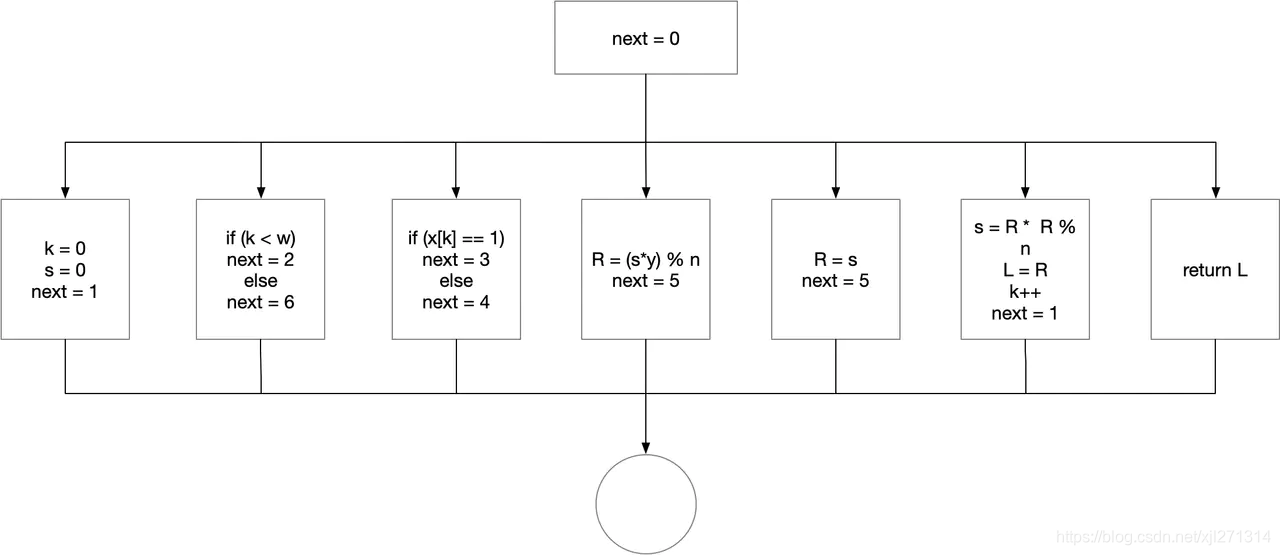
直观的感觉就是代码变扁了,所有的代码都挤到了一层当中,这样做的好处在于在让攻击者无法直观,或通过静态分析的方法判断哪些代码先执行哪些后执行,必须要通过动态运行才能记录执行顺序,从而加重了分析的负担。
WARNING
需要注意的是,在我们的流程中,无论是顺序流程还是条件流程,如果出现了块作用域的变量声明(const/let),那么上面的流程扁平化将会出现错误,因为 switch/case 内部为块作用域,表达式被分到 case 内部之后,其他 case 无法取到 const/let 的变量声明,自然会报错。
不透明谓词
上面的 switch/case 的判断是通过数字(也就是谓词)的形式判断的,而且是透明的,可以看到的,为了更加的混淆视听,可以将 case 判断设定为表达式,让其无法直接判断,比如利用上面代码,改为不透明谓词:
function modexp(y, x, w, n) {
var a = 0,
b = 1,
c = 2 * b + a;
var R, L, s, k;
var next = 0;
for (;;) {
switch (next) {
case a * b:
k = 0;
s = 1;
next = 1;
break;
case 2 * a + b:
if (k < w) next = 2;
else next = 6;
break;
case 2 * b - a:
if (x[k] == 1) next = 3;
else next = 4;
break;
case 3 * a + b + c:
R = (s * y) % n;
next = 5;
break;
case 2 * b + c:
R = s;
next = 5;
break;
case 2 * c + b:
s = (R * R) % n;
L = R;
k++;
next = 1;
break;
case 4 * c - 2 * b:
return L;
}
}
}
谓词用 a、b、c 三个变量组成,甚至可以把这三个变量隐藏到全局中定义,或者隐藏在某个数组中,让攻击者不能那么轻易找到。
脚本加壳
脚本加壳指的是将脚本进行编码,运行时 解码 再
eval执行如:
eval (…………………………..……………. ……………. !@#$%^&* ……………. .…………………………..……………. );
但是实际上这样意义并不大,因为攻击者只需要 alert 或者 console.log 就原形毕露了。
改进方案:利用 Function / (function(){}).constructor 将代码当做字符串传入,然后执行,如下:
var code = 'console.log("hellow")';
new Function(code)();
如上代码,可以对 code 进行加密混淆,例如aaencode,原理也是如此,我们举个例子:
alert("Hello, JavaScript");
利用 aaencode 混淆过后,代码如下:
゚ω゚ノ= /`m´)ノ ~┻━┻ //*´∇`*/ ['_']; o=(゚ー゚) =_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚: '_' ,゚ω゚ノ : ((゚ω゚ノ==3) +'_') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ '_')[o^_^o -(゚Θ゚)] ,゚Д゚ノ:((゚ー゚==3) +'_')[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ==3) +'_') [c^_^o];(゚Д゚) ['c'] = ((゚Д゚)+'_') [ (゚ー゚)+(゚ー゚)-(゚Θ゚) ];(゚Д゚) ['o'] = ((゚Д゚)+'_') [゚Θ゚];(゚o゚)=(゚Д゚) ['c']+(゚Д゚) ['o']+(゚ω゚ノ +'_')[゚Θ゚]+ ((゚ω゚ノ==3) +'_') [゚ー゚] + ((゚Д゚) +'_') [(゚ー゚)+(゚ー゚)]+ ((゚ー゚==3) +'_') [゚Θ゚]+((゚ー゚==3) +'_') [(゚ー゚) - (゚Θ゚)]+(゚Д゚) ['c']+((゚Д゚)+'_') [(゚ー゚)+(゚ー゚)]+ (゚Д゚) ['o']+((゚ー゚==3) +'_') [゚Θ゚];(゚Д゚) ['_'] =(o^_^o) [゚o゚] [゚o゚];(゚ε゚)=((゚ー゚==3) +'_') [゚Θ゚]+ (゚Д゚) .゚Д゚ノ+((゚Д゚)+'_') [(゚ー゚) + (゚ー゚)]+((゚ー゚==3) +'_') [o^_^o -゚Θ゚]+((゚ー゚==3) +'_') [゚Θ゚]+ (゚ω゚ノ +'_') [゚Θ゚]; (゚ー゚)+=(゚Θ゚); (゚Д゚)[゚ε゚]='\\'; (゚Д゚).゚Θ゚ノ=(゚Д゚+ ゚ー゚)[o^_^o -(゚Θ゚)];(o゚ー゚o)=(゚ω゚ノ +'_')[c^_^o];(゚Д゚) [゚o゚]='\"';(゚Д゚) ['_'] ( (゚Д゚) ['_'] (゚ε゚+(゚Д゚)[゚o゚]+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚o゚]) (゚Θ゚)) ('_');
这段代码看起来很奇怪,不像是 JavaScript 代码,但是实际上这段代码是用一些看似表情的符号,声明了一个 16 位的数组(用来表示 16 进制位置),然后将 code 当做字符串遍历,把每个代码符号通过 string.charCodeAt 取这个 16 位的数组下标,拼接成代码。大概的意思就是把代码当做字符串,然后使用这些符号的拼接代替这一段代码(可以看到代码里有很多加号),最后,通过(new Function(code))('_')执行。
仔细观察上面这一段代码,把代码最后的('_')去掉,在运行,你会直接看到源代码,然后 Function.constructor 存在(゚ Д ゚)变量中,感兴趣的同学可以自行查看。
反调试
由于 JavaScript 自带 debugger 语法,我们可以利用死循环性的 debugger,当页面打开调试面板的时候,无限进入调试状态。
定时执行
在代码开始执行的时候,使用 setInterval 定时触发我们的反调试函数。
随机执行
在代码生成阶段,随机在部分函数体中注入我们的反调试函数,当代码执行到特定逻辑的时候,如果调试面板在打开状态,则无限进入调试状态。
内容监测
由于我们的代码可能已经反调试了,攻击者可以会将代码拷贝到自己本地,然后修改,调试,执行,这个时候就需要添加一些检测进行判定,如果不是正常的环境执行,那让代码自行失败。
代码自检
在代码生成的时候,为函数生成一份 Hash,在代码执行之前,通过函数 toString 方法,检测代码是否被篡改。
function module() {
// 篡改校验
if (Hash(module.toString()) != "JkYxnHlxHbqKowiuy") {
// 代码被篡改!
}
}
环境自检
检查当前脚本的执行环境,例如当前的 URL 是否在允许的白名单内、当前环境是否正常的浏览器。
如果为 Nodejs 环境,如果出现异常环境,甚至我们可以启动木马,长期跟踪。
废代码注入
插入一些永远不会发生的代码,让攻击者在分析代码的时候被这些无用的废代码混淆视听,增加阅读难度。
废逻辑注入
与废代码相对立的就是有用的代码,这些有用的代码代表着被执行代码的逻辑,这个时候我们可以收集这些逻辑,增加一段判定来决定执行真逻辑还是假逻辑,如下:
(function() {
if (true) {
var foo = function() {
console.log("abc");
};
var bar = function() {
console.log("def");
};
var baz = function() {
console.log("ghi");
};
var bark = function() {
console.log("jkl");
};
var hawk = function() {
console.log("mno");
};
foo();
bar();
baz();
bark();
hawk();
}
})();
可以看到,所有的 console.log 都是我们的执行逻辑,这个时候可以收集所有的 console.log,然后制造假判定来执行真逻辑代码,收集逻辑注入后如下:
(function() {
if (true) {
var foo = function() {
if ("aDas" === "aDas") {
console.log("abc");
} else {
console.log("def");
}
};
var bar = function() {
if ("Mfoi" !== "daGs") {
console.log("ghi");
} else {
console.log("def");
}
};
var baz = function() {
if ("yuHo" === "yuHo") {
console.log("ghi");
} else {
console.log("abc");
}
};
var bark = function() {
if ("qu2o" === "qu2o") {
console.log("jkl");
} else {
console.log("mno");
}
};
var hawk = function() {
if ("qCuo" !== "qcuo") {
console.log("jkl");
} else {
console.log("mno");
}
};
foo();
bar();
baz();
bark();
hawk();
}
})();
判定逻辑中生成了一些字符串,在没有使用字符串提取的情况下,这是可以通过代码静态分析来得到真实的执行逻辑的,或者我们可以使用上文讲到的动态执行来决定执行真逻辑,可以看一下使用字符串提取和变量名编码后的效果,如下:
var _0x6f5a = [
"abc",
"def",
"caela",
"hmexe",
"ghi",
"aaeem",
"maxex",
"mno",
"jkl",
"ladel",
"xchem",
"axdci",
"acaeh",
"log",
];
(function(_0x22c909, _0x4b3429) {
var _0x1d4bab = function(_0x2e4228) {
while (--_0x2e4228) {
_0x22c909["push"](_0x22c909["shift"]());
}
};
_0x1d4bab(++_0x4b3429);
})(_0x6f5a, 0x13f);
var _0x2386 = function(_0x5db522, _0x143eaa) {
_0x5db522 = _0x5db522 - 0x0;
var _0x50b579 = _0x6f5a[_0x5db522];
return _0x50b579;
};
(function() {
if (!![]) {
var _0x38d12d = function() {
if (_0x2386("0x0") !== _0x2386("0x1")) {
console[_0x2386("0x2")](_0x2386("0x3"));
} else {
console[_0x2386("0x2")](_0x2386("0x4"));
}
};
var _0x128337 = function() {
if (_0x2386("0x5") !== _0x2386("0x6")) {
console[_0x2386("0x2")](_0x2386("0x4"));
} else {
console[_0x2386("0x2")](_0x2386("0x7"));
}
};
var _0x55d92e = function() {
if (_0x2386("0x8") !== _0x2386("0x8")) {
console[_0x2386("0x2")](_0x2386("0x3"));
} else {
console[_0x2386("0x2")](_0x2386("0x7"));
}
};
var _0x3402dc = function() {
if (_0x2386("0x9") !== _0x2386("0x9")) {
console[_0x2386("0x2")](_0x2386("0xa"));
} else {
console[_0x2386("0x2")](_0x2386("0xb"));
}
};
var _0x28cfaa = function() {
if (_0x2386("0xc") === _0x2386("0xd")) {
console[_0x2386("0x2")](_0x2386("0xb"));
} else {
console[_0x2386("0x2")](_0x2386("0xa"));
}
};
_0x38d12d();
_0x128337();
_0x55d92e();
_0x3402dc();
_0x28cfaa();
}
})();
求值陷阱
除了注入执行逻辑以外,还可以埋入一个隐蔽的陷阱,在一个永不到达且无法静态分析的分支里,引用该函数,正常用户不会执行,而 AST 遍历求值时,则会触发陷阱!陷阱能干啥呢?
- 日志上报,及时了解情况
- 在本地存储隐写特征,长期跟踪
- 释放 CSRF 漏洞,获得破解者的详细信息
- 开启自杀程序(页面崩溃、死循环、耗尽内存等)
加壳干扰
将代码用 eval 包裹,然后对 eval 参数进行加密,并埋下陷阱,在解码时插入无用代码,干扰显示,大量换行、注释、字符串等大量特殊字符,导致显示卡顿。
总结
上述混淆方法,单个特性使用的话,混淆效果一般,各个特性组合起来用的话,最终效果很明显,当然这个看个人需求,毕竟混淆是个双刃剑,在增加了阅读难度的同时,也增大了脚本的体积,降低了代码的运行效率。
建议针对某些核心代码可以进行加密混淆。