前端错误监控体系搭建
- 2020.03-30
一直以来,如何定位前端上线后的错误,都是一个很头疼的问题,因为它发生于用户的一系列操作之后。原因可能是机型,网络环境,接口请求,复杂的操作行为等等,在我们想要去解决的时候很难复现出来,自然也就无法解决。因此搭建一个良好的前端错误监控体系就显得十分重要。
如果你家里有矿的话,可以尝试使用FunDebug直接集成,付费使用
前端监控功能主要包含:
JS 错误日志监控分析
静态资源请求报错统计
用户行为检索
接口请求报错统计
HTML加载性能分析PV、UV日志分析https://www.cnblogs.com/warm-stranger/p/8837784.html
前端错误异常情况

错误采集常用信息
| 字段 | 类型 | 解释 |
|---|---|---|
| requestId | String | 一个界面产生一个 requestId |
| traceId | String | 一个阶段产生一个 traceId,用于追踪和一个异常相关的所有日志记录 |
| hash | String | 这条 log 的唯一标识码,相当于 logId,但它是根据当前日志记录的具体内容而生成的 |
| time | Number | 当前日志产生的时间(保存时刻) |
| userId | String | 当前用户 id |
| userStatus | Number | 当时,用户状态信息(是否可用/禁用) |
| userRoles | Array | 当时,前用户的角色列表 |
| userGroups | Array | 当时,用户当前所在组,组别权限可能影响结果 |
| userLicenses | Array | 当时,许可证,可能过期 |
| path | String | 所在路径,URL |
| action | String | 进行了什么操作 |
| referer | String | 上一个路径,来源 URL |
| prevAction | String | 上一个操作 |
| data | Object | 当前界面的 state、data |
| dataSources | Array<Object> | 上游 api 给了什么数据 |
| dataSend | Object | 提交了什么数据 |
| targetElement | HTMLElement | 用户操作的 DOM 元素 |
| targetDOMPath | Array<HTMLElement> | 该 DOM 元素的节点路径 |
| targetCSS | Object | 该元素的自定义样式表 |
| targetAttrs | Object | 该元素当前的属性及值 |
| errorType | String | 错误类型 |
| errorLevel | String | 异常级别 |
| errorStack | String | 错误 stack 信息 |
| errorFilename | String | 出错文件 |
| errorLineNo | Number | 出错行 |
| errorColNo | Number | 出错列位置 |
| errorMessage | String | 错误描述(开发者定义) |
| errorTimeStamp | Number | 时间戳 |
| eventType | String | 事件类型 |
| pageX | Number | 事件 x 轴坐标 |
| pageY | Number | 事件 y 轴坐标 |
| screenX | Number | 事件 x 轴坐标 |
| screenY | Number | 事件 y 轴坐标 |
| pageW | Number | 页面宽度 |
| pageH | Number | 页面高度 |
| screenW | Number | 屏幕宽度 |
| screenH | Number | 屏幕高度 |
| eventKey | String | 触发事件的键 |
| network | String | 网络环境描述 |
| userAgent | String | 客户端描述 |
| device | String | 设备描述 |
| system | String | 操作系统描述 |
| appVersion | String | 应用版本 |
| apiVersion | String | 接口版本 |
JS 错误日志监控分析
- 2020.05.09
1.try...catch
通过try...catch我们能够知道出错的信息,并且也有堆栈信息可以知道在哪个文件第几行第几列发生错误
try {
let name = "jartto";
console.log(nam);
} catch (err) {
console.log(err.message);
}
缺点:
没法捕捉
try,catch块,当前代码块有语法错误,JS 解释器压根都不会执行当前这个代码块,所以也就没办法被catch住;没法捕捉到全局的错误事件,也即是只有
try,catch的块里边运行出错才会被你捕捉到,这里的块你要理解成一个函数块.无法捕获到异常,这是需要我们特别注意的地方。
try {
setTimeout(() => {
undefined.map((v) => v);
}, 1000);
} catch (e) {
console.log("捕获到异常:", e);
}
2.全局捕获 window.onerror
当 JS 运行时错误发生时,window 会触发一个 ErrorEvent 接口的 error 事件,并执行 window.onerror()。
window.onerror一样可以拿到出错的信息以及文件名、行号、列号等信息,还可以在window.onerror最后return true让浏览器不输出错误信息到控制台.
/**
* @param {string} msg 错误信息。直观的错误描述信息,不过有时候你确实无法从这里面看出端倪,特别是压缩后脚本的报错信息,可能让你更加疑惑。
* @param {string} url 发生错误对应的脚本路径。
* @param {number} line 错误发生的行号。
* @param {number} column 错误发生的列号。
* @param {object} error 具体的 error 对象,继承自 window.Error 的某一类,部分属性和前面几项有重叠,但是包含更加详细的错误调用堆栈信息,这对于定位错误非常有帮助。
*/
window.onerror = function(msg, url, line, column, error) {
console.log("window error catch:", msg, url, line, column, error);
// 返回 true 则错误消息不显示在控制台,返回 false,则错误消息将会展示在控制台
return true;
};
// 完整版
window.onerror = function(msg, url, line, col, error) {
// 没有URL不上报!上报也不知道错误
if (msg != "Script error." && !url) {
return true;
}
setTimeout(function() {
var data = {};
// 不一定所有浏览器都支持col参数
col = col || (window.event && window.event.errorCharacter) || 0;
data.url = url;
data.line = line;
data.col = col;
data.time = Date.now();
if (!!error && !!error.stack) {
// 如果浏览器有堆栈信息
// 直接使用
data.msg = error.stack.toString();
} else if (!!arguments.callee) {
// 尝试通过callee拿堆栈信息
var ext = [];
var f = arguments.callee.caller,
c = 3;
// 这里只拿三层堆栈信息
while (f && --c > 0) {
ext.push(f.toString());
if (f === f.caller) {
break; //如果有环
}
f = f.caller;
}
ext = ext.join(",");
data.msg = ext;
}
// 把data上报到后台!
console.log(data);
}, 0);
return true;
};
WARNING
我们发现,不论是语法错误、静态资源异常,或者接口异常,通过window.onerror错误都无法捕获到。
onerror 最好写在所有 JS 脚本的前面,否则有可能捕获不到错误。
3.图片等资源加载报错
// img script link 资源加载出错
function dynamicSourceLoadError() {
const links = document.querySelectorAll("link");
const imgs = [...document.querySelectorAll("img")];
const scripts = document.querySelectorAll("script");
console.log(links, imgs, scripts);
imgs.map((item) => {
item.onLoad = () => {
console.log("load");
};
console.log(item);
});
}
4.performance.getEntries()
performance是 h5 的新特性之一,使用该方法能获取到当前页面已经加载到的资源,返回的是一个数组对象。

例子:获取页面中没有成功加载的图片资源
- 通过
performance.getEntries()获取已经加载了的图片资源
const arr = [];
const reg = /\.jpg$|\.jpeg$|.png$|\.gif$/i;
performance.getEntries().forEach((item) => {
if (reg.test(item.name)) {
arr.push(item.name);
}
});
- 获取页面中所有的
img标签
const imgs = [...document.querySelectorAll("img")];
- 利用获取到的 img 的长度减去已经加载到的长度,如果大于 0 的部分,就是加载失败的
const arr = [];
const reg = /\.jpg$|\.jpeg$|.png$|\.gif$/i;
performance.getEntries().forEach((item) => {
if (reg.test(item.name)) {
arr.push(item.name);
}
});
const imgs = [...document.querySelectorAll("img")];
const failNum = imgs.length - arr.length;
return failNum;
5.Error 事件捕获
当一项资源(如图片或脚本)加载失败,加载资源的元素会触发一个 Event 接口的 error 事件,并执行该元素上的onerror()处理函数。这些 error 事件不会向上冒泡到 window ,不过(至少在 Firefox 中)能被单一的window.addEventListener捕获。
// window.addEventListener第三个参数是true的时候是捕获的过程,false是冒泡的过程
window.addEventListener(
"error",
function(e) {
console.log("捕获error", e);
},
true
);
TIP
由于网络请求异常不会事件冒泡,因此必须在捕获阶段将其捕捉到才行,但是这种方式虽然可以捕捉到网络请求的异常,但是无法判断 HTTP 的状态是 404 还是其他比如 500 等等,所以还需要配合服务端日志才进行排查分析才可以。
WARNING
不同浏览器下返回的
error对象可能不同,需要注意兼容处理。需要注意避免
addEventListener重复监听。
6.Promise Catch
在 promise 中使用 catch 可以非常方便的捕获到异步 error ,这个很简单。
WARNING
没有写 catch 的 Promise 中抛出的错误无法被 onerror 或 try-catch 捕获到,所以我们务必要在 Promise 中不要忘记写 catch 处理抛出的异常。
解决方案: 为了防止有漏掉的 Promise 异常,建议在全局增加一个对 unhandledrejection 的监听,用来全局监听Uncaught Promise Error。使用方式:
window.addEventListener("unhandledrejection", function(e) {
// 去掉控制台显示的话加上
e.preventDefault();
console.log(e);
});
7.Vue errorHandler
Vue.config.errorHandler = (err, vm, info) => {
console.error("通过vue errorHandler捕获的错误");
console.error(err);
console.error(vm);
console.error(info);
};
8.React 异常捕获
可以在发生错误的时候渲染一些错误的页面。
import React, { Component } from "react";
export default class ErrorCatch extends Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
componentDidCatch(error, info) {
this.setState({ hasError: true });
// 在这里可以做异常的上报
console.log("componentDidCatch:", info);
}
render() {
if (this.state.hasError) {
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
9.iframe 异常
对于 iframe 的异常捕获,我们还得借力 window.onerror:
window.onerror = function(message, source, lineno, colno, error) {
console.log("捕获到异常:", { message, source, lineno, colno, error });
};
简单的例子:
<iframe src="./iframe.html" frameborder="0"></iframe>
<script>
window.frames[0].onerror = function (message, source, lineno, colno, error) {
console.log('捕获到 iframe 异常:',{message, source, lineno, colno, error});
return true;
};
</script>
10.Script error
一般情况,如果出现 Script error 这样的错误,基本上可以确定是出现了跨域问题。这时候,是不会有其他太多辅助信息的,但是解决思路无非如下:
TIP
跨源资源共享机制( CORS ):我们为 script 标签添加 crossOrigin 属性。
<script src="http://jartto.wang/main.js" crossorigin></script>
或者动态去添加 js 脚本:
const script = document.createElement("script");
script.crossOrigin = "anonymous";
script.src = url;
document.body.appendChild(script);
WARNING
特别注意,服务器端需要设置:Access-Control-Allow-Origin
11.崩溃和卡顿
卡顿也就是网页暂时响应比较慢, JS 可能无法及时执行。但崩溃就不一样了,网页都崩溃了,JS 都不运行了,还有什么办法可以监控网页的崩溃,并将网页崩溃上报呢。
- 利用
window对象的load和beforeunload事件实现了网页崩溃的监控。 不错的文章,推荐阅读:Logging Information on Browser Crashes
window.addEventListener("load", function() {
sessionStorage.setItem("good_exit", "pending");
setInterval(function() {
sessionStorage.setItem("time_before_crash", new Date().toString());
}, 1000);
});
window.addEventListener("beforeunload", function() {
sessionStorage.setItem("good_exit", "true");
});
if (
sessionStorage.getItem("good_exit") &&
sessionStorage.getItem("good_exit") !== "true"
) {
/*
insert crash logging code here
*/
alert(
"Hey, welcome back from your crash, looks like you crashed on: " +
sessionStorage.getItem("time_before_crash")
);
}
- 随着 PWA 概念的流行,大家对 Service Worker 也逐渐熟悉起来。基于以下原因,我们可以使用
Service Worker来实现网页崩溃的监控
Service Worker有自己独立的工作线程,与网页区分开,网页崩溃了,Service Worker一般情况下不会崩溃;Service Worker生命周期一般要比网页还要长,可以用来监控网页的状态;网页可以通过
navigator.serviceWorker.controller.postMessage API向掌管自己的SW发送消息。
基于以上几点,我们可以实现一种基于心跳检测的监控方案:
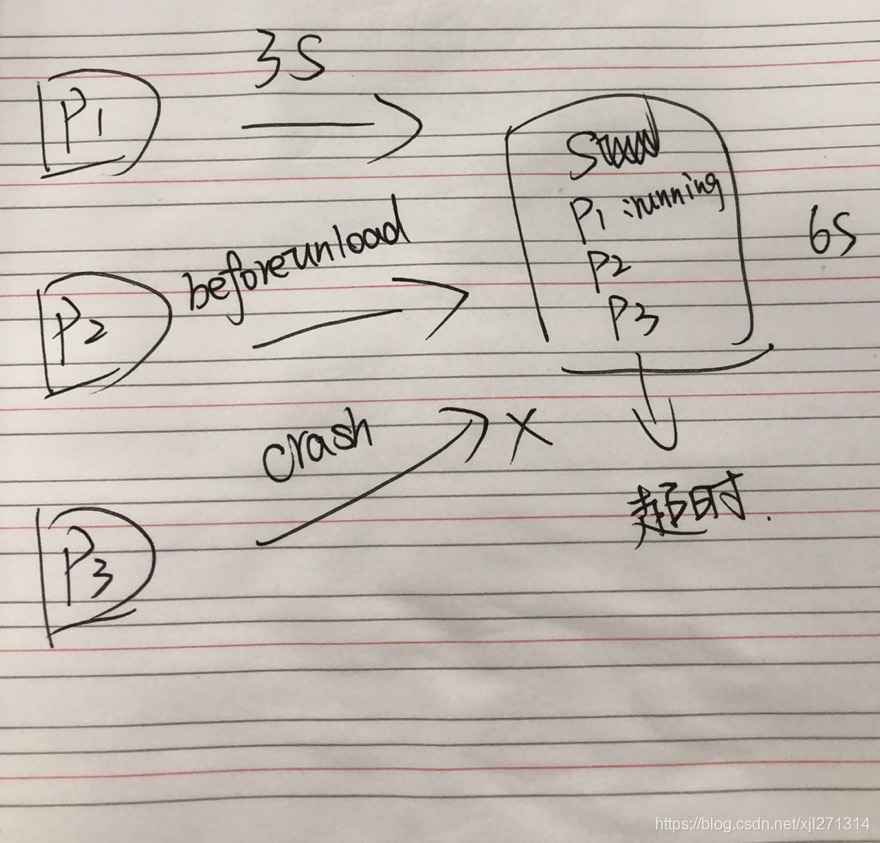
p1:网页加载后,通过
postMessage API每 3s 给 sw 发送一个心跳,表示自己的在线,sw 将在线的网页登记下来,更新登记时间;p2:网页在
beforeunload时,通过postMessage API告知自己已经正常关闭,sw 将登记的网页清除;p3:如果网页在运行的过程中
crash了,sw 中的running状态将不会被清除,更新时间停留在奔溃前的最后一次心跳;sw:
Service Worker每 6s 查看一遍登记中的网页,发现登记时间已经超出了一定时间(比如 9s)即可判定该网页crash了。
部分示例代码:
// 页面 JavaScript 代码
if (navigator.serviceWorker.controller !== null) {
let HEARTBEAT_INTERVAL = 5 * 1000; // 每五秒发一次心跳
let sessionId = uuid();
let heartbeat = function() {
navigator.serviceWorker.controller.postMessage({
type: "heartbeat",
id: sessionId,
data: {}, // 附加信息,如果页面 crash,上报的附加数据
});
};
window.addEventListener("beforeunload", function() {
navigator.serviceWorker.controller.postMessage({
type: "unload",
id: sessionId,
});
});
setInterval(heartbeat, HEARTBEAT_INTERVAL);
heartbeat();
}
sessionId本次页面会话的唯一 id;postMessage附带一些信息,用于上报crash需要的数据,比如当前页面的地址等等。
// sw.js
const CHECK_CRASH_INTERVAL = 10 * 1000; // 每 10s 检查一次
const CRASH_THRESHOLD = 15 * 1000; // 15s 超过15s没有心跳则认为已经 crash
const pages = {};
let timer;
function checkCrash() {
const now = Date.now();
for (var id in pages) {
let page = pages[id];
if (now - page.t > CRASH_THRESHOLD) {
// 上报 crash
delete pages[id];
}
}
if (Object.keys(pages).length == 0) {
clearInterval(timer);
timer = null;
}
}
worker.addEventListener("message", (e) => {
const data = e.data;
if (data.type === "heartbeat") {
pages[data.id] = {
t: Date.now(),
};
if (!timer) {
timer = setInterval(function() {
checkCrash();
}, CHECK_CRASH_INTERVAL);
}
} else if (data.type === "unload") {
delete pages[data.id];
}
});
12.压缩代码如何定位到脚本异常位置
线上的代码几乎都经过了压缩处理,几十个文件打包成了一个并丑化代码,当我们收到 a is not defined 的时候,我们根本不知道这个变量 a 究竟是什么含义,此时报错的错误日志显然是无效的。
第一想到的办法是利用 sourcemap 定位到错误代码的具体位置,详细内容可以参考:Sourcemap 定位脚本错误
另外也可以通过在打包的时候,在每个合并的文件之间添加几行空格,并相应加上一些注释,这样在定位问题的时候很容易可以知道是哪个文件报的错误,然后再通过一些关键词的搜索,可以快速地定位到问题的所在位置。
示例 · 压缩代码定位错误困难
源代码(存在错误):
function test() {
noerror; // <- 报错
}
test();
经 webpack 打包压缩后产生如下代码:
!(function(n) {
function r(e) {
if (t[e]) return t[e].exports;
var o = (t[e] = { i: e, l: !1, exports: {} });
return n[e].call(o.exports, o, o.exports, r), (o.l = !0), o.exports;
}
var t = {};
(r.m = n),
(r.c = t),
(r.i = function(n) {
return n;
}),
(r.d = function(n, t, e) {
r.o(n, t) ||
Object.defineProperty(n, t, {
configurable: !1,
enumerable: !0,
get: e,
});
}),
(r.n = function(n) {
var t =
n && n.__esModule
? function() {
return n.default;
}
: function() {
return n;
};
return r.d(t, "a", t), t;
}),
(r.o = function(n, r) {
return Object.prototype.hasOwnProperty.call(n, r);
}),
(r.p = ""),
r((r.s = 0));
})([
function(n, r) {
function t() {
noerror;
}
t();
},
]);
代码如期报错,并上报相关信息
{
msg: 'Uncaught ReferenceError: noerror is not defined',
url: 'http://127.0.0.1:8077/main.min.js',
row: '1',
col: '515'
}
此时,错误信息中行列数为 1 和 515。 结合压缩后的代码,肉眼观察很难定位出具体问题。
如何定位到具体错误
1. 不压缩 js 代码
这种方式简单粗暴,但存在明显问题:1. 源代码泄漏,2. 文件的大小大大增加。
2. 将压缩代码中分号变成换行
uglifyjs 有一个叫 semicolons 配置参数,设置为 false 时,会将压缩代码中的分号替换为换行符,提高代码可读性, 如:
!(function(n) {
function r(e) {
if (t[e]) return t[e].exports;
var o = (t[e] = { i: e, l: !1, exports: {} });
return n[e].call(o.exports, o, o.exports, r), (o.l = !0), o.exports;
}
var t = {};
(r.m = n),
(r.c = t),
(r.i = function(n) {
return n;
}),
(r.d = function(n, t, e) {
r.o(n, t) ||
Object.defineProperty(n, t, {
configurable: !1,
enumerable: !0,
get: e,
});
}),
(r.n = function(n) {
var t =
n && n.__esModule
? function() {
return n.default;
}
: function() {
return n;
};
return r.d(t, "a", t), t;
}),
(r.o = function(n, r) {
return Object.prototype.hasOwnProperty.call(n, r);
}),
(r.p = ""),
r((r.s = 0));
})([
function(n, r) {
function t() {
noerror;
}
t();
},
]);
此时,错误信息中行列数为 5 和 137,查找起来比普通压缩方便不少。但仍会出现一行中有很多代码,不容易定位的问题。
3.js 代码半压缩 · 保留空格和换行
uglifyjs 的另一配置参数 beautify 设置为 true 时,最终代码将呈现压缩后进行格式化的效果(保留空格和换行),如
!(function(n) {
// ...
// ...
})([
function(n, r) {
function t() {
noerror;
}
t();
},
]);
此时,错误信息中行列数为 32 和 9,能够快速定位到具体位置,进而对应到源代码。但由于增加了换行和空格,所以文件大小有所增加。
4.SourceMap 快速定位
SourceMap 是一个信息文件,存储着源文件的信息及源文件与处理后文件的映射关系。
在定位压缩代码的报错时,可以通过错误信息的行列数与对应的 SourceMap 文件,处理后得到源文件的具体错误信息。
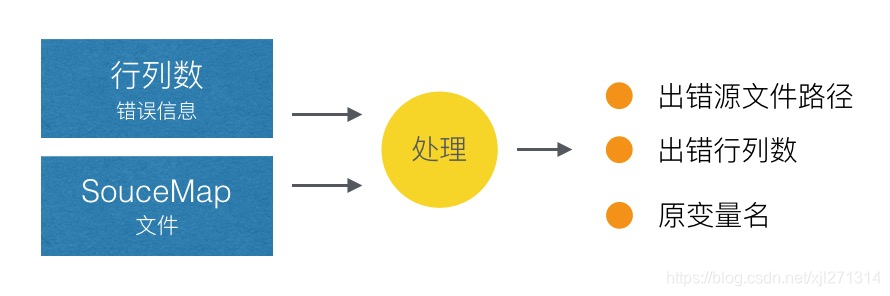
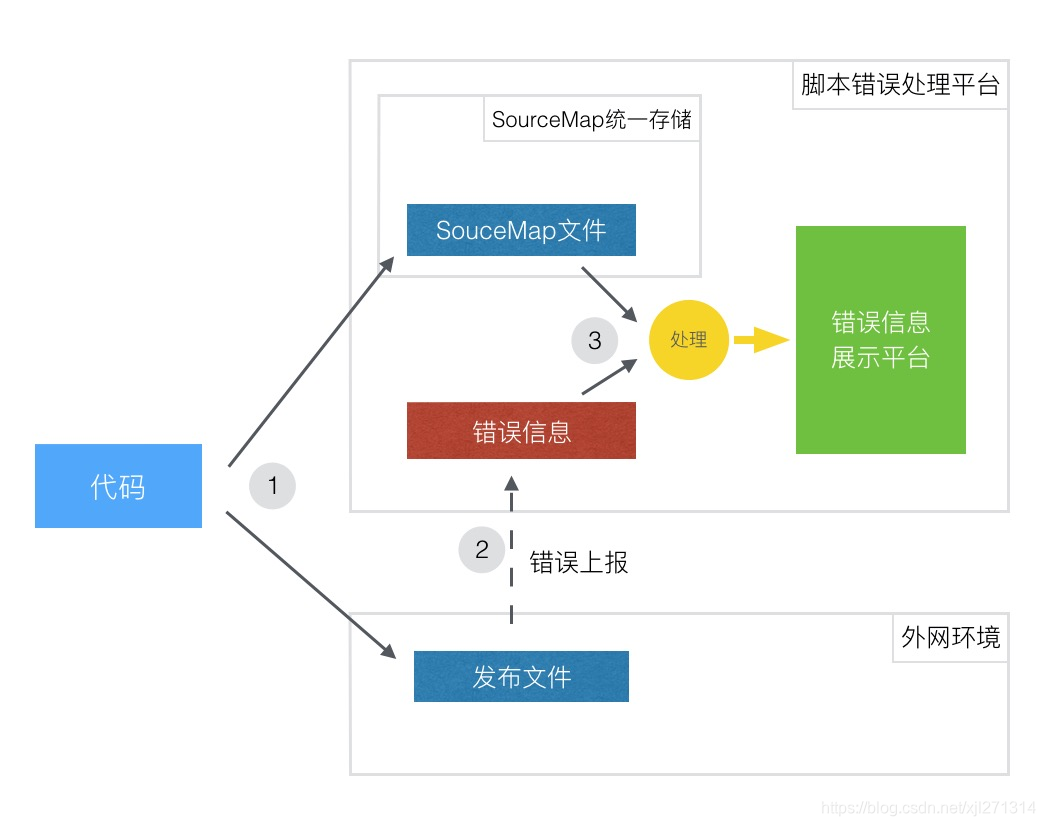
SourceMap 文件中的 sourcesContent 字段对应源代码内容,不希望将 SourceMap 文件发布到外网上,而是将其存储到脚本错误处理平台上,只用在处理脚本错误中。
通过 SourceMap 文件可以得到源文件的具体错误信息,结合 sourcesContent 上源文件的内容进行可视化展示,让报错信息一目了然!
基于SourceMap 快速定位脚本报错方案
5.开源方案 sentry
sentry 是一个实时的错误日志追踪和聚合平台,包含了上面 sourcemap 方案,并支持更多功能,如:错误调用栈,log 信息,issue管理,多项目,多用户,提供多种语言客户端等,具体介绍可以查看 getsentry/sentry,sentry.io,这里暂不展开。
13.错误上报
- 通过 Ajax 发送数据
因为 Ajax 请求本身也有可能会发生异常,而且有可能会引发跨域问题,一般情况下更推荐使用动态创建 img 标签的形式进行上报。
- 动态创建 img 标签的形式
function report(error) {
let reportUrl = "http://xxx/report";
new Image().src = `${reportUrl}?logs=${error}`;
}
收集异常信息量太多,怎么办?实际中,我们不得不考虑这样一种情况:如果你的网站访问量很大,那么一个必然的错误发送的信息就有很多条,这时候,我们需要设置采集率,从而减缓服务器的压力
Reporter.send = function(data) {
// 只采集 30%
if (Math.random() < 0.3) {
send(data); // 上报错误信息
}
};
这个采集率可以通过具体实际的情况来设定,方法多样化,可以使用一个随机数,也可以具体根据用户的某些特征来进行判定。
14.错误上报的方式拓展
1. 前端存储日志
我们并不单单采集异常本身日志,而且还会采集与异常相关的用户行为日志。单纯一条异常日志并不能帮助我们快速定位问题根源,找到解决方案。但如果要收集用户的行为日志,又要采取一定的技巧,而不能用户每一个操作后,就立即将该行为日志传到服务器。
对于具有大量用户同时在线的应用,如果用户一操作就立即上传日志,无异于对日志服务器进行DDOS攻击。因此,我们先将这些日志存储在用户客户端本地,达到一定条件之后,再同时打包上传一组日志。
那么,如何进行前端日志存储呢?我们不可能直接将这些日志用一个变量保存起来,这样会挤爆内存,而且一旦用户进行刷新操作,这些日志就丢失了,因此,我们自然而然想到前端数据持久化方案
目前,可用的持久化方案可选项也比较多了,主要有:Cookie、localStorage、sessionStorage、IndexedDB、webSQL 、FileSystem 等等。那么该如何选择呢?我们通过一个表来进行对比:
| 存储方式 | cookie | localStorage | sessionStorage | IndexedDB | webSQL | FileSystem |
|---|---|---|---|---|---|---|
| 类型 | key-value | key-value | key-value | NoSQL | SQL | \ |
| 数据格式 | string | string | string | object | \ | \ |
| 容量 | 4k | 5M | 5M | 500M | 60M | \ |
| 进程 | 同步 | 同步 | 同步 | 异步 | 异步 | \ |
| 检索 | \ | key | key | key,index | field | \ |
| 性能 | 读快写慢 | 读快写慢 | 读快写慢 | 读慢写快 | 读慢写快 | \ |
综合之后,IndexedDB是最好的选择,它具有容量大、异步的优势,异步的特性保证它不会对界面的渲染产生阻塞。
而且IndexedDB是分库的,每个库又分store,还能按照索引进行查询,具有完整的数据库管理思维,比localStorage更适合做结构化数据管理。但是它有一个缺点,就是 api 非常复杂,不像 localStorage 那么简单直接。
针对这一点,我们可以使用 hello-indexeddb 这个工具,它用 Promise 对复杂 api 进行来封装,简化操作,使 IndexedDB 的使用也能做到 localStorage 一样便捷。另外,IndexedDB 是被广泛支持的 HTML5 标准,兼容大部分浏览器,因此不用担心它的发展前景。
接下来,我们究竟应该怎么合理使用IndexedDB,保证我们前端存储的合理性呢?
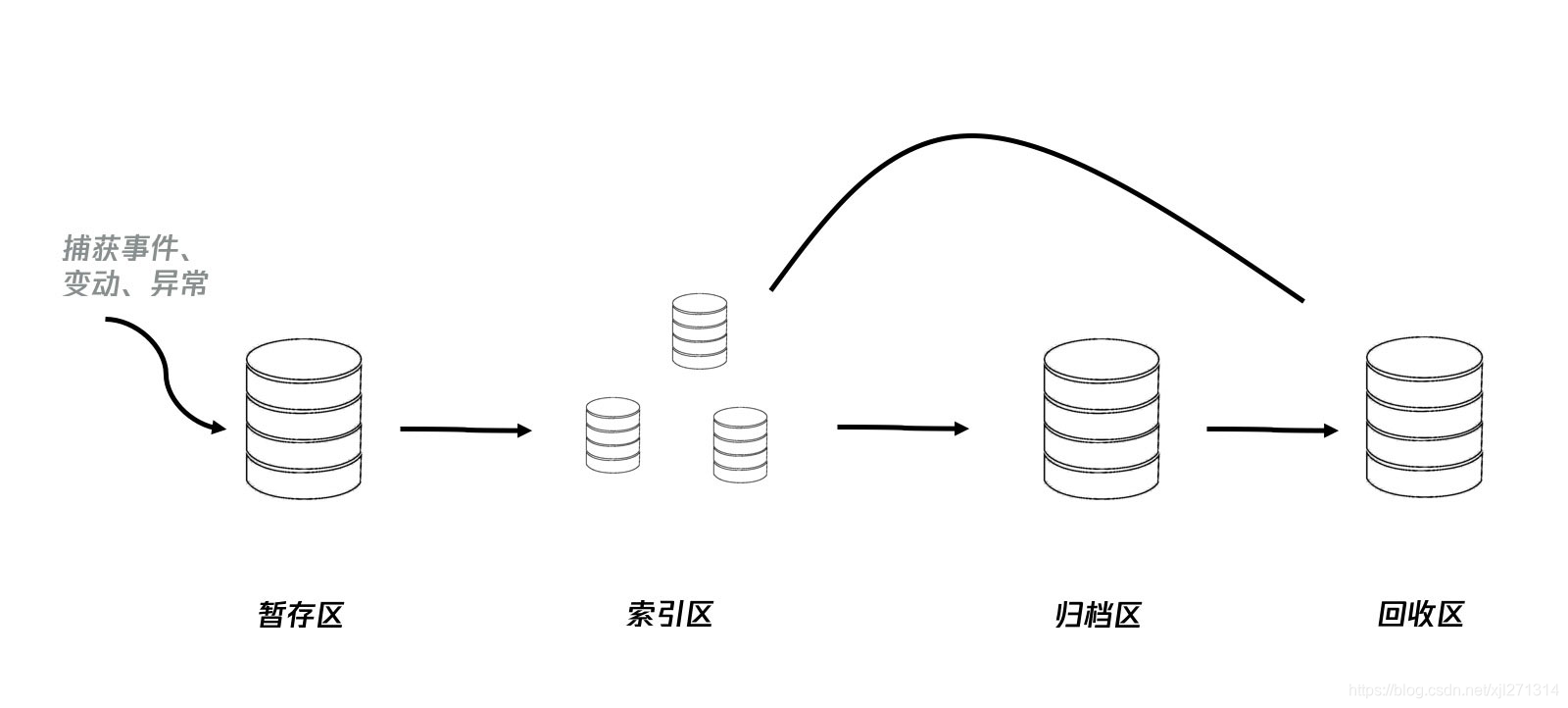
上图展示了前端存储日志的流程和数据库布局。当一个事件、变动、异常被捕获之后,形成一条初始日志,被立即放入暂存区(indexedDB 的一个 store),之后主程序就结束了收集过程,后续的事只在 webworker 中发生。
在一个 webworker 中,一个循环任务不断从暂存区中取出日志,对日志进行分类,将分类结果存储到索引区中,并对日志记录的信息进行丰富,将最终将会上报到服务端的日志记录转存到归档区。而当一条日志在归档区中存在的时间超过一定天数之后,它就已经没有价值了,但是为了防止特殊情况,它被转存到回收区,再经历一段时间后,就会被从回收区中清除。
2.前端整理日志
上文讲到,在一个webworker中对日志进行整理后存到索引区和归档区,那么这个整理过程是怎样的呢?
由于我们下文要讲的上报,是按照索引进行的,因此,我们在前端的日志整理工作,主要就是根据日志特征,整理出不同的索引。我们在收集日志时,会给每一条日志打上一个 type,以此进行分类,并创建索引,同时通过object-hashcode计算每个log对象的hash值,作为这个 log 的唯一标志。
- 将所有日志记录按时序存放在归档区,并将新入库的日志加入索引
BatchIndexes:批量上报索引(包含性能等其他日志),可一次批量上报 100 条MomentIndexes:即时上报索引,一次全部上报FeedbackIndexes:用户反馈索引,一次上报一条BlockIndexes:区块上报索引,按异常/错误(traceId,requestId)分块,一次上报一块- 上报完成后,被上报过的日志对应的索引删除
- 3 天以上日志进入回收区
- 7 天以上的日志从回收区清除
rquestId:同时追踪前后端日志。由于后端也会记录自己的日志,因此,在前端请求 api 的时候,默认带上 requestId,后端记录的日志就可以和前端日志对应起来。
traceId:追踪一个异常发生前后的相关日志。当应用启动时,创建一个 traceId,直到一个异常发生时,刷新 traceId。把一个 traceId 相关的 requestId 收集起来,把这些 requestId 相关的日志组合起来,就是最终这个异常相关的所有日志,用来对异常进行复盘。
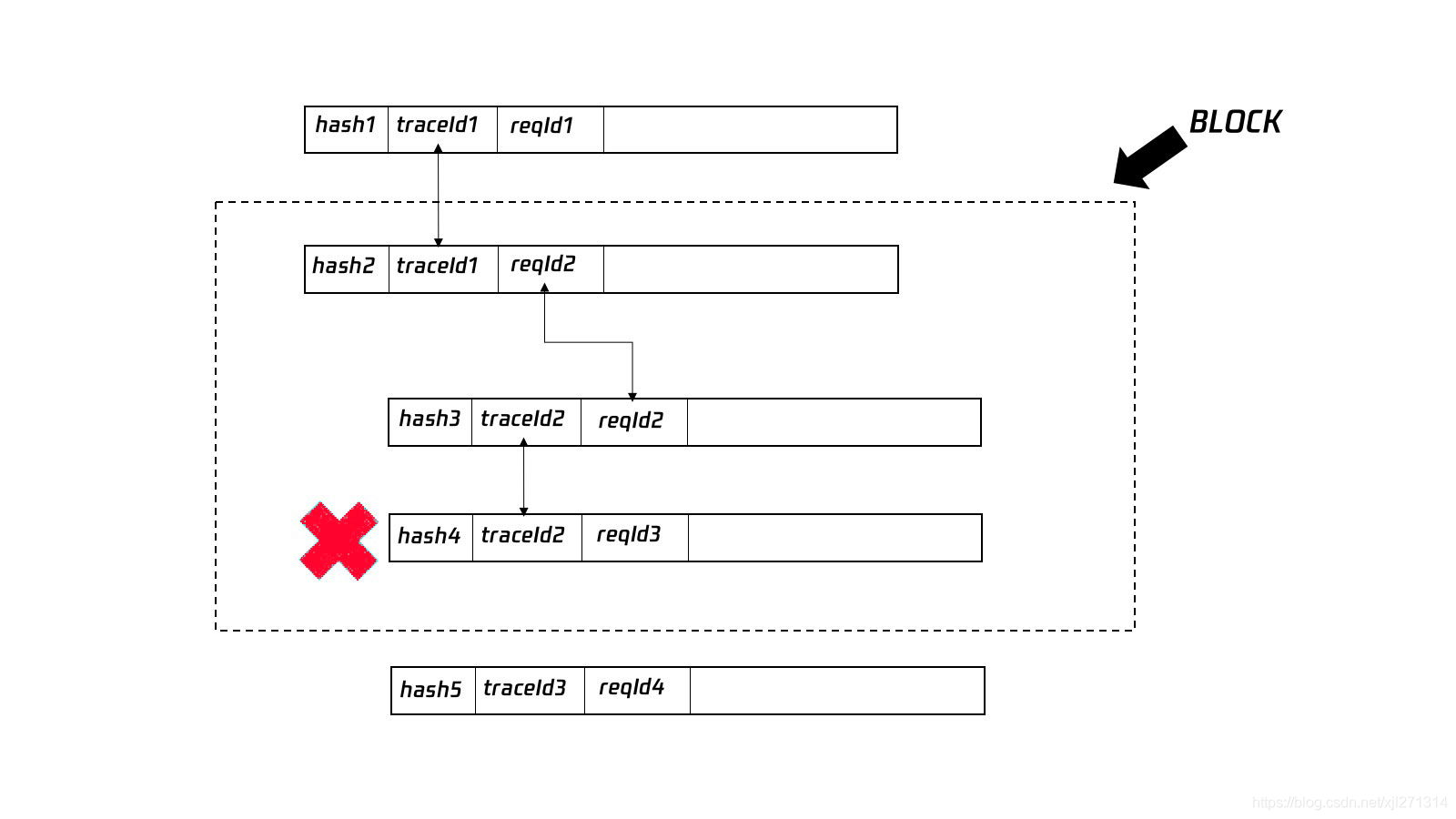
上图举例展示了如何利用 traceId 和 requestId 找出和一个异常相关的所有日志。
在上图中,hash4 是一条异常日志,我们找到 hash4 对应的 traceId 为 traceId2,在日志列表中,有两条记录具有该 traceId,但是 hash3 这条记录并不是一个动作的开始,因为 hash3 对应的 requestId 为 reqId2,而 reqId2 开始于 hash2,因此,我们实际上要把 hash2 也加入到该异常发生的整个复盘备选记录中。
总结起来就是,我们要找出同一个 traceId 对应的所有 requestId 对应的日志记录,虽然有点绕,但稍理解就可以明白其中的道理。
我们把这些和一个异常相关的所有日志集合起来,称为一个 block,再利用日志的 hash 集合,得出这个 block 的 hash,并在索引区中建立索引,等待上报。
3.上报日志
上报日志也在 webworker 中进行,为了和整理区分,可以分两个 worker。上报的流程大致为:在每一个循环中,从索引区取出对应条数的索引,通过索引中的 hash,到归档区取出完整的日志记录,再上传到服务器。
按照上报的频率(重要紧急度)可将上报分为四种:
a. 即时上报
收集到日志后,立即触发上报函数。仅用于 A 类异常。而且由于受到网络不确定因素影响,A 类日志上报需要有一个确认机制,只有确认服务端已经成功接收到该上报信息之后,才算完成。否则需要有一个循环机制,确保上报成功。
b. 批量上报
将收集到的日志存储在本地,当收集到一定数量之后再打包一次性上报,或者按照一定的频率(时间间隔)打包上传。这相当于把多次合并为一次上报,以降低对服务器的压力。
c. 区块上报
将一次异常的场景打包为一个区块后进行上报。它和批量上报不同,批量上报保证了日志的完整性,全面性,但会有无用信息。而区块上报则是针对异常本身的,确保单个异常相关的日志被全部上报。
d. 用户主动提交
在界面上提供一个按钮,用户主动反馈 bug。这有利于加强与用户的互动。
或者当异常发生时,虽然对用户没有任何影响,但是应用监控到了,弹出一个提示框,让用户选择是否愿意上传日志。这种方案适合涉及用户隐私数据时。
| \ | 即时上报 | 批量上报 | 区块上报 | 用户反馈 |
|---|---|---|---|---|
| 时效 | 立即 | 定时 | 稍延时 | 延时 |
| 条数 | 一次全部上报 | 一次 100 条 | 单次上报相关条目 | 一次 1 条 |
| 容量 | 小 | 中 | – | – |
| 紧急 | 紧急重要 | 不紧急 | 不紧急但重要 | 不紧急 |
即时上报虽然叫即时,但是其实也是通过类似队列的循环任务去完成的,它主要是尽快把一些重要的异常提交给监控系统,好让运维人员发现问题,因此,它对应的紧急程度比较高。
TIP
批量上报和区块上报的区别:
批量上报是一次上报一定条数,比如每 2 分钟上报 1000 条,直到上报完成。
而区块上报是在异常发生之后,马上收集和异常相关的所有日志,查询出哪些日志已经由批量上报上报过了,剔除掉,把其他相关日志上传,和异常相关的这些日志相对而言更重要一些,它们可以帮助尽快复原异常现场,找出发生异常的根源。
用户提交的反馈信息,则可以慢悠悠上报上去。
为了确保上报是成功的,在上报时需要有一个确认机制,由于在服务端接收到上报日志之后,并不会立即存入数据库,而是放到一个队列中,因此,前后端在确保日志确实已经记录进数据库这一点上需要再做一些处理。
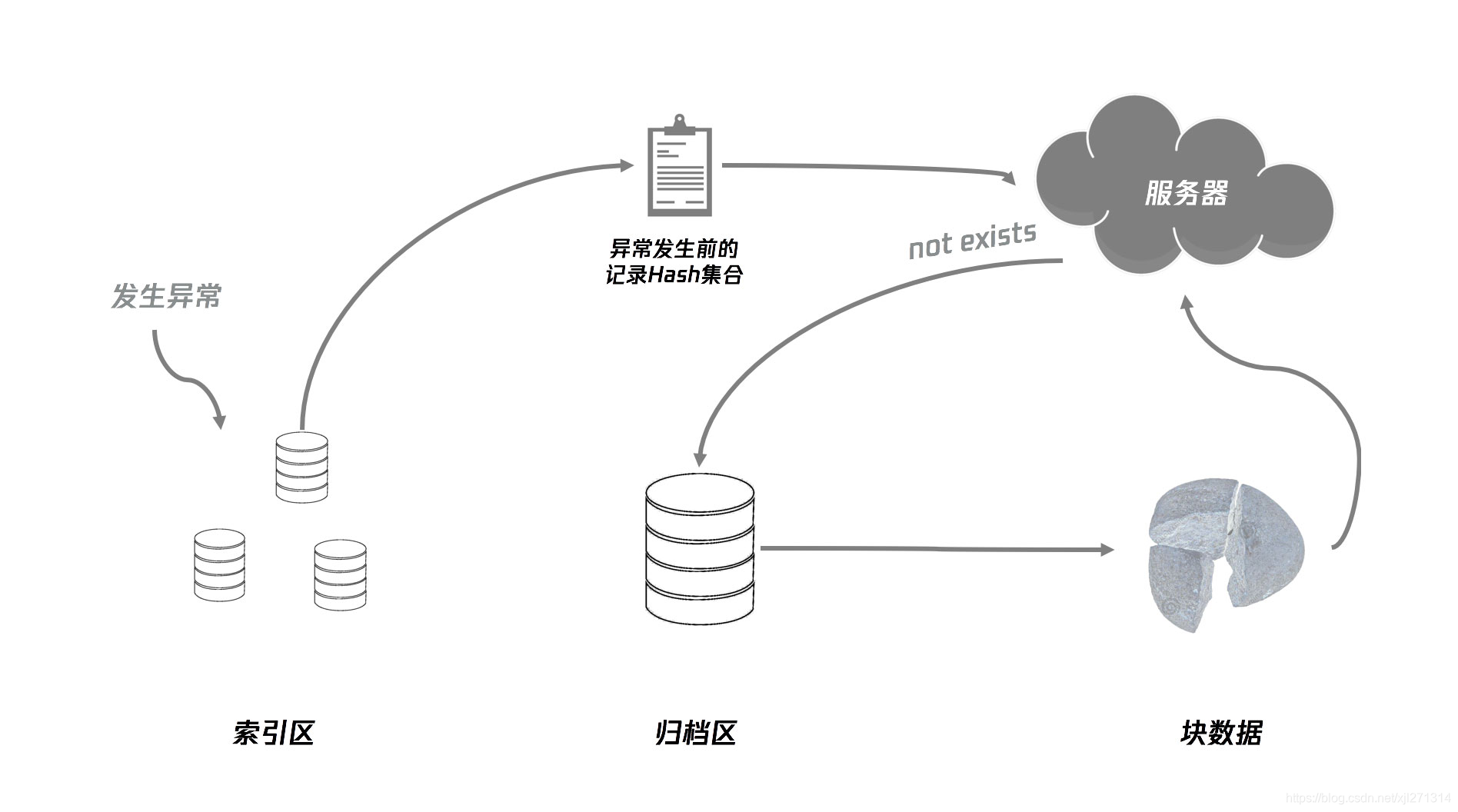
上图展示了上报的一个大致流程,在上报时,先通过 hash 查询,让客户端知道准备要上报的日志集合中,是否存在已经被服务端保存好的日志,如果已经存在,就将这些日志去除,避免重复上报,浪费流量。
4.压缩上报数据
一次性上传批量数据时,必然遇到数据量大,浪费流量,或者传输慢等情况,网络不好的状态下,可能导致上报失败。因此,在上报之前进行数据压缩也是一种方案。
对于合并上报这种情况,一次的数据量可能要十几 k,对于日 pv 大的站点来说,产生的流量还是很可观的。所以有必要对数据进行压缩上报。
lz-string是一个非常优秀的字符串压缩类库,兼容性好,代码量少,压缩比高,压缩时间短,压缩率达到惊人的 60%。
但它基于LZ78压缩,如果后端不支持解压,可选择 gzip 压缩,一般而言后端会默认预装 gzip,因此,选择 gzip 压缩数据也可以,工具包 pako 中自带了 gzip 压缩,可以尝试使用。
15. 监控与通知
对异常进行统计和分析只是基础,而在发现异常时可以推送和告警,甚至做到自动处理,才是一个异常监控系统应该具备的能力。
1.自定义触发条件的告警
a. 监控实现
当日志信息进入接入层时,就可以触发监控逻辑。当日志信息中存在较为高级别的异常时,也可以立即出发告警。告警消息队列和日志入库队列可以分开来管理,实现并行。
对入库日志信息进行统计,对异常信息进行告警。对监控异常进行响应。所谓监控异常,是指:有规律的异常一般而言都比较让人放心,比较麻烦的是突然之间的异常。例如在某一时段突然频繁接收到 D 级异常,虽然 D 级异常是不紧急一般重要,但是当监控本身发生异常时,就要提高警惕。
b. 自定义触发条件
除了系统开发时配置的默认告警条件,还应该提供给日志管理员可配置的自定义触发条件。
- 日志内含有什么内容时
- 日志统计达到什么度、量时
- 向符合什么条件的用户告警
2.推送渠道
可选择的途径有很多,例如邮件、短信、微信、电话。
3.推送频率
针对不同级别的告警,推送的频率也可以进行设定。低风险告警可以以报告的形式一天推送一次,高风险告警 10 分钟循环推送,直到处理人手动关闭告警开关。
4.自动报表
对于日志统计信息的推送,可以做到自动生成日报、周报、月报、年报并邮件发送给相关群组。
5.自动产生 bug 工单
当异常发生时,系统可以调用工单系统 API 实现自动生成 bug 单,工单关闭后反馈给监控系统,形成对异常处理的追踪信息进行记录,在报告中予以展示。
16.修复异常
1.sourcemap
前端代码大部分情况都是经过压缩后发布的,上报的 stack 信息需要还原为源码信息,才能快速定位源码进行修改。
发布时,只部署 js 脚本到服务器上,将 sourcemap 文件上传到监控系统,在监控系统中展示 stack 信息时,利用 sourcemap 文件对 stack 信息进行解码,得到源码中的具体信息。
但是这里有一个问题,就是 sourcemap 必须和正式环境的版本对应,还必须和 git 中的某个 commit 节点对应,这样才能保证在查异常的时候可以正确利用 stack 信息,找到出问题所在版本的代码。这些可以通过建立 CI 任务,在集成化部署中增加一个部署流程,以实现这一环节。
2.从告警到预警
预警的本质是,预设可能出现异常的条件,当触发该条件时异常并没有真实发生,因此,可以赶在异常发生之前对用户行为进行检查,及时修复,避免异常或异常扩大。
怎么做呢?其实就是一个统计聚类的过程。将历史中发生异常的情况进行统计,从时间、地域、用户等不同维度加以统计,找出规律,并将这些规律通过算法自动加入到预警条件中,当下次触发时,及时预警。
3.智能修复
自动修复错误。例如,前端要求接口返回数值,但接口返回了数值型的字符串,那么可以有一种机制,监控系统发送正确数据类型模型给后端,后端在返回数据时,根据该模型控制每个字段的类型。
总结
- 可疑区域增加
Try-Catch - 全局监控 JS 异常
window.onerror - 全局监控静态资源异常
window.addEventListener - 捕获没有
Catch的Promise异常:unhandledrejection VUE errorHandler和React componentDidCatch- 监控网页崩溃:
window对象的load和beforeunload - 跨域
crossOrigin解决
错误信息采集方法
封装的通用采集方法
// 设置日志对象类的通用属性
function setCommonProperty() {
this.happenTime = new Date().getTime(); // 日志发生时间
this.webMonitorId = WEB_MONITOR_ID; // 用于区分应用的唯一标识(一个项目对应一个)
this.simpleUrl = window.location.href.split("?")[0].replace("#", ""); // 页面的url
this.customerKey = utils.getCustomerKey(); // 用于区分用户,所对应唯一的标识,清理本地数据后失效
this.pageKey = utils.getPageKey(); // 用于区分页面,所对应唯一的标识,每个新页面对应一个值
this.deviceName = DEVICE_INFO.deviceName;
this.os =
DEVICE_INFO.os + (DEVICE_INFO.osVersion ? " " + DEVICE_INFO.osVersion : "");
this.browserName = DEVICE_INFO.browserName;
this.browserVersion = DEVICE_INFO.browserVersion;
// TODO 位置信息, 待处理
this.monitorIp = ""; // 用户的IP地址
this.country = "china"; // 用户所在国家
this.province = ""; // 用户所在省份
this.city = ""; // 用户所在城市
// 用户自定义信息, 由开发者主动传入, 便于对线上进行准确定位
this.userId = USER_INFO.userId;
this.firstUserParam = USER_INFO.firstUserParam;
this.secondUserParam = USER_INFO.secondUserParam;
}
// JS错误日志,继承于日志基类MonitorBaseInfo
function JavaScriptErrorInfo(uploadType, errorMsg, errorStack) {
setCommonProperty.apply(this);
this.uploadType = uploadType;
this.errorMessage = encodeURIComponent(errorMsg);
this.errorStack = errorStack;
this.browserInfo = BROWSER_INFO;
}
JavaScriptErrorInfo.prototype = new MonitorBaseInfo();
启动 JS 错误监控代码
/**
* 页面JS错误监控
*/
function recordJavaScriptError() {
// 重写console.error, 可以捕获更全面的报错信息
var oldError = console.error;
console.error = function() {
// arguments的长度为2时,才是error上报的时机
// if (arguments.length < 2) return;
var errorMsg = arguments[0] && arguments[0].message;
var url = WEB_LOCATION;
var lineNumber = 0;
var columnNumber = 0;
var errorObj = arguments[0] && arguments[0].stack;
if (!errorObj) errorObj = arguments[0];
// 如果onerror重写成功,就无需在这里进行上报了
!jsMonitorStarted &&
siftAndMakeUpMessage(errorMsg, url, lineNumber, columnNumber, errorObj);
return oldError.apply(console, arguments);
};
// 重写 onerror 进行jsError的监听
window.onerror = function(errorMsg, url, lineNumber, columnNumber, errorObj) {
jsMonitorStarted = true;
var errorStack = errorObj ? errorObj.stack : null;
siftAndMakeUpMessage(errorMsg, url, lineNumber, columnNumber, errorStack);
};
function siftAndMakeUpMessage(
origin_errorMsg,
origin_url,
origin_lineNumber,
origin_columnNumber,
origin_errorObj
) {
var errorMsg = origin_errorMsg ? origin_errorMsg : "";
var errorObj = origin_errorObj ? origin_errorObj : "";
var errorType = "";
if (errorMsg) {
var errorStackStr = JSON.stringify(errorObj);
errorType = errorStackStr.split(": ")[0].replace('"', "");
}
var javaScriptErrorInfo = new JavaScriptErrorInfo(
JS_ERROR,
errorType + ": " + errorMsg,
errorObj
);
javaScriptErrorInfo.handleLogInfo(JS_ERROR, javaScriptErrorInfo);
}
}
数据上传方法:
/**
* 添加一个定时器,进行数据的上传
* 2秒钟进行一次URL是否变化的检测
* 10秒钟进行一次数据的检查并上传
*/
var timeCount = 0;
setInterval(function() {
checkUrlChange();
// 循环5后次进行一次上传
if (timeCount >= 25) {
// 如果是本地的localhost, 就忽略,不进行上传
var logInfo =
(localStorage[ELE_BEHAVIOR] || "") +
(localStorage[JS_ERROR] || "") +
(localStorage[HTTP_LOG] || "") +
(localStorage[SCREEN_SHOT] || "") +
(localStorage[CUSTOMER_PV] || "") +
(localStorage[LOAD_PAGE] || "") +
(localStorage[RESOURCE_LOAD] || "");
if (logInfo) {
localStorage[ELE_BEHAVIOR] = "";
localStorage[JS_ERROR] = "";
localStorage[HTTP_LOG] = "";
localStorage[SCREEN_SHOT] = "";
localStorage[CUSTOMER_PV] = "";
localStorage[LOAD_PAGE] = "";
localStorage[RESOURCE_LOAD] = "";
utils.ajax(
"POST",
HTTP_UPLOAD_LOG_INFO,
{
logInfo: logInfo,
},
function(res) {},
function() {}
);
}
timeCount = 0;
}
timeCount++;
}, 200);
静态资源加载监控
很多时候资源加载报错对前端项目来说是致命的,因为静态资源加载出错了,有可能就会导致前端页面无法渲染,用户就只能对着一个空白屏幕发呆,不知所措。
如何监控前端静态资源加载情况?
正常情况下,html 页面中主要包含的静态资源有:js 文件、css 文件、图片文件,这些文件加载失败将直接对页面造成影响甚至瘫痪,所有我们需要把他们统计出来。我不太确定是否需要把所有静态资源文件的加载信息都统计下来,既然加载成功了,页面正常了,应该就没有统计的必要了,所以我们只统计加载出错的情况。
先说一下监控方法:
使用
script标签的回调方法,在网络上搜索过,看到有人说可以用onerror方法监控报错的情况, 但是经过试验后,发现并没有监控到报错情况,至少在静态资源跨域加载的时候是无法获取的。利用
performance.getEntries()方法,获取到所有加载成功的资源列表,在onload事件中遍历出所有页面资源集合,利用排除法,到所有集合中过滤掉成功的资源列表,即为加载失败的资源。 此方法看似合理,也确实能够排查出加载失败的静态资源,但是检查的时机很难掌握,另外,如果遇到异步加载的js也就歇菜了。添加一个
Listener(error)来捕获前端的异常,也是我正在使用的方法,比较靠谱。但是这个方法会监控到很多的error, 所以我们要从中筛选出静态资源加载报错的error, 代码如下:
/**
* 监控页面静态资源加载报错
*/
function recordResourceError() {
// 当浏览器不支持 window.performance.getEntries 的时候,用下边这种方式
window.addEventListener(
"error",
function(e) {
var typeName = e.target.localName;
var sourceUrl = "";
if (typeName === "link") {
sourceUrl = e.target.href;
} else if (typeName === "script") {
sourceUrl = e.target.src;
}
var resourceLoadInfo = new ResourceLoadInfo(
RESOURCE_LOAD,
sourceUrl,
typeName,
"0"
);
resourceLoadInfo.handleLogInfo(RESOURCE_LOAD, resourceLoadInfo);
},
true
);
}
用户行为追踪功能
使用过 fundebug 的小伙伴都知道其提供了一个 bug 截屏追踪的功能。但是实际实现中存在着图片上传流量消耗过大的问题。要怎么适中的解决这个问题呢?
首先肯定要对上传的图片进行压缩操作
如果用户量非常多, 用户频繁的上传,也是一个大问题。
所以,我的建议是分散流量,让每个用户为我们贡献至少一次页面截图:
每个用户都在随机的页面,随机的时间上传一个页面截图,以及一个点击区域截图,有且仅上传一次,一个用户的生命周期中只贡献一次页面截图。
每个用户发生某一类错误时,也只需上传一个截图即可,多个类型的错误,则上传多个截图。这样可以大量节省用户的上传次数。
用户的截图数据很大, 时间长了需要很大的硬盘空间, 所以我的建议是,每个流程页面,只需要对应一个(点击区域截图,同理)。 每个用户的某一种类型的错误页面也只对应一个(方便定位错误原因)。
完整的实现代码如下:
/**
* js处理截图
*/
this.screenShot = function(cntElem, callback) {
var shareContent = cntElem; //需要截图的包裹的(原生的)DOM 对象
var width = shareContent.offsetWidth; //获取dom 宽度
var height = shareContent.offsetHeight; //获取dom 高度
var canvas = document.createElement("canvas"); //创建一个canvas节点
var scale = 0.6; //定义任意放大倍数 支持小数
canvas.style.display = "none";
canvas.width = width * scale; //定义canvas 宽度 * 缩放
canvas.height = height * scale; //定义canvas高度 *缩放
canvas.getContext("2d").scale(scale, scale); //获取context,设置scale
var opts = {
scale: scale, // 添加的scale 参数
canvas: canvas, //自定义 canvas
logging: false, //日志开关,便于查看html2canvas的内部执行流程
width: width, //dom 原始宽度
height: height,
useCORS: true, // 【重要】开启跨域配置
};
// 前端装的插件 用于执行html页面截图
html2canvas(cntElem, opts).then(function(canvas) {
var dataURL = canvas.toDataURL();
var tempCompress = dataURL.replace("data:image/png;base64,", "");
// lz-string 执行对字符串长度的压缩
var compressedDataURL = Base64String.compress(tempCompress);
callback(compressedDataURL);
});
};
接口请求监控篇
可能有人会认为接口的报错应该由后台来关注,统计,并修复。 确实如此,而且后台服务有了很多成熟完善的统计工具,完全能够应对大部分的异常情况, 那么为什么还需要前端对接口请求进行监控呢。
原因很简单,因为前端是 bug 的第一发现位置,在你帮后台背锅之前怎么快速把过甩出去呢,这时候,我们就需要有一个接口的监控系统,哈哈 :)那么,我们需要哪些监控数据才能够把锅甩出去呢?
我们要监控所有的接口请求
我们要监控并记录所有接口请求的返回状态和返回结果
我们要监控接口的报错情况,及时定位线上问题产生的原因
我们要分析接口的性能,以辅助我们对前端应用的优化。
如何监控前端接口请求呢?
一般前端请求都是用ajax请求,也有用fetch请求的,以及前端框架自己封装的请求等等。总之他们封装的方法各不相同,但是万变不离其宗,他们都是对浏览器的这个对象 window.XMLHttpRequest 进行了封装,所以我们只要能够监听到这个对象的一些事件,就能够把请求的信息分离出来。
- 监听 ajax 请求
/**
* 页面接口请求监控
*/
function recordHttpLog() {
// 监听ajax的状态
function ajaxEventTrigger(event) {
var ajaxEvent = new CustomEvent(event, {
detail: this,
});
window.dispatchEvent(ajaxEvent);
}
var oldXHR = window.XMLHttpRequest;
function newXHR() {
var realXHR = new oldXHR();
realXHR.addEventListener(
"loadstart",
function() {
ajaxEventTrigger.call(this, "ajaxLoadStart");
},
false
);
realXHR.addEventListener(
"loadend",
function() {
ajaxEventTrigger.call(this, "ajaxLoadEnd");
},
false
);
// 此处的捕获的异常会连日志接口也一起捕获,如果日志上报接口异常了,就会导致死循环了。
// realXHR.onerror = function () {
// siftAndMakeUpMessage("Uncaught FetchError: Failed to ajax", WEB_LOCATION, 0, 0, {});
// }
return realXHR;
}
function handleHttpResult(i, tempResponseText) {
if (!timeRecordArray[i] || timeRecordArray[i].uploadFlag === true) {
return;
}
var responseText = "";
try {
responseText = tempResponseText
? JSON.stringify(utils.encryptObj(JSON.parse(tempResponseText)))
: "";
} catch (e) {
responseText = "";
}
var simpleUrl = timeRecordArray[i].simpleUrl;
var currentTime = new Date().getTime();
var url = timeRecordArray[i].event.detail.responseURL;
var status = timeRecordArray[i].event.detail.status;
var statusText = timeRecordArray[i].event.detail.statusText;
var loadTime = currentTime - timeRecordArray[i].timeStamp;
if (!url || url.indexOf(HTTP_UPLOAD_LOG_API) != -1) return;
var httpLogInfoStart = new HttpLogInfo(
HTTP_LOG,
simpleUrl,
url,
status,
statusText,
"发起请求",
"",
timeRecordArray[i].timeStamp,
0
);
httpLogInfoStart.handleLogInfo(HTTP_LOG, httpLogInfoStart);
var httpLogInfoEnd = new HttpLogInfo(
HTTP_LOG,
simpleUrl,
url,
status,
statusText,
"请求返回",
responseText,
currentTime,
loadTime
);
httpLogInfoEnd.handleLogInfo(HTTP_LOG, httpLogInfoEnd);
// 当前请求成功后就,就将该对象的uploadFlag设置为true, 代表已经上传了
timeRecordArray[i].uploadFlag = true;
}
var timeRecordArray = [];
window.XMLHttpRequest = newXHR;
window.addEventListener("ajaxLoadStart", function(e) {
var tempObj = {
timeStamp: new Date().getTime(),
event: e,
simpleUrl: window.location.href.split("?")[0].replace("#", ""),
uploadFlag: false,
};
timeRecordArray.push(tempObj);
});
window.addEventListener("ajaxLoadEnd", function() {
for (var i = 0; i < timeRecordArray.length; i++) {
// uploadFlag == true 代表这个请求已经被上传过了
if (timeRecordArray[i].uploadFlag === true) continue;
if (timeRecordArray[i].event.detail.status > 0) {
var rType = (
timeRecordArray[i].event.detail.responseType + ""
).toLowerCase();
if (rType === "blob") {
(function(index) {
var reader = new FileReader();
reader.onload = function() {
var responseText = reader.result; //内容就在这里
handleHttpResult(index, responseText);
};
try {
reader.readAsText(
timeRecordArray[i].event.detail.response,
"utf-8"
);
} catch (e) {
handleHttpResult(
index,
timeRecordArray[i].event.detail.response + ""
);
}
})(i);
} else {
var responseText = timeRecordArray[i].event.detail.responseText;
handleHttpResult(i, responseText);
}
}
}
});
}
一个页面上会有很多个请求,当一个页面发出多个请求的时候,ajaxLoadStart事件被监听到,但是却无法区分出来到底发送的是哪个请求,只返回了一个内容超多的事件对象,而且事件对象的内容几乎完全一样。
当ajaxLoadEnd事件被监听到的时候,也会返回一个内容超多的时间对象,这个时候事件对象里包含了接口请求的所有信息。幸运的是,两个对象是同一个引用,也就意味着,ajaxLoadStart和ajaxLoadEnd事件被捕获的时候,他们作用的是用一个对象。那我们就有办法分析出来了。
当ajaxLoadStart事件发生的时候,我们将回调方法中的事件对象全都放进数组timeRecordArray里,当ajaxLoadEnd发生的时候,我们就去遍历这个数据,遇到又返回结果的事件对象,说明接口请求已经完成,记录下来,并从数组中将该事件对象的uploadFlag属性设置为true, 代表请求已经被记录。这样我们就能够逐一分析出接口请求的内容了。
- 监听 fetch 请求
通过第一种方法,已经能够监听到大部分的ajax请求了。然而,使用fetch请求的人越来越多,因为fetch的链式调用可以让我们摆脱ajax的嵌套地狱,被更多的人所青睐。奇怪的是,我用第一种方式,却无法监听到fetch的请求事件,这是为什么呢?
return new Promise(function(resolve, reject) {
var request = new Request(input, init);
var xhr = new XMLHttpRequest();
xhr.onload = function() {
var options = {
status: xhr.status,
statusText: xhr.statusText,
headers: parseHeaders(xhr.getAllResponseHeaders() || ""),
};
options.url =
"responseURL" in xhr
? xhr.responseURL
: options.headers.get("X-Request-URL");
var body = "response" in xhr ? xhr.response : xhr.responseText;
resolve(new Response(body, options));
};
// .......
xhr.send(typeof request._bodyInit === "undefined" ? null : request._bodyInit);
});
这个是fetch的一段源码, 可以看到,它创建了一个Promise, 并新建了一个XMLHttpRequest对象 var xhr =newXMLHttpRequest()。
由于fetch的代码是内置在浏览器中的,它必然先用监控代码执行,所以,我们在添加监听事件的时候,是无法监听fetch里边的XMLHttpRequest对象的。
怎么办呢,我们需要重写一下fetch的代码。只要在监控代码执行之后,我们重写一下fetch,就可以正常监听使用fetch方式发送的请求了。
// 设置日志对象类的通用属性
function setCommonProperty() {
this.happenTime = new Date().getTime(); // 日志发生时间
this.webMonitorId = WEB_MONITOR_ID; // 用于区分应用的唯一标识(一个项目对应一个)
this.simpleUrl = window.location.href.split("?")[0].replace("#", ""); // 页面的url
this.completeUrl = utils.b64EncodeUnicode(
encodeURIComponent(window.location.href)
); // 页面的完整url
this.customerKey = utils.getCustomerKey(); // 用于区分用户,所对应唯一的标识,清理本地数据后失效,
// 用户自定义信息, 由开发者主动传入, 便于对线上问题进行准确定位
var wmUserInfo = localStorage.wmUserInfo
? JSON.parse(localStorage.wmUserInfo)
: "";
this.userId = utils.b64EncodeUnicode(wmUserInfo.userId || "");
this.firstUserParam = utils.b64EncodeUnicode(wmUserInfo.firstUserParam || "");
this.secondUserParam = utils.b64EncodeUnicode(
wmUserInfo.secondUserParam || ""
);
}
// 接口请求日志,继承于日志基类MonitorBaseInfo
function HttpLogInfo(
uploadType,
url,
status,
statusText,
statusResult,
currentTime,
loadTime
) {
setCommonProperty.apply(this);
this.uploadType = uploadType; // 上传类型
this.httpUrl = utils.b64EncodeUnicode(encodeURIComponent(url)); // 请求地址
this.status = status; // 接口状态
this.statusText = statusText; // 状态描述
this.statusResult = statusResult; // 区分发起和返回状态
this.happenTime = currentTime; // 客户端发送时间
this.loadTime = loadTime; // 接口请求耗时
}
使用 Nodejs 搭建消息队列
日志上传如何缓解高并发的情况呢?我们分为三个小点来处理。
1.增加日志上传的时间间隔
正如我们所知,日志上传的时间间隔越长,用户在这个间隔内离开的几率就会越大,日志的漏传量就会增加,然后会导致日志的准确度降低。因为我们的探针是安插在浏览器内的,用户随时都有可能关掉,所以,理论上讲间隔越短越好,但这并不现实。所以这个需要在服务器的承受能力和日志的准确率之间做个权衡,由具体情况而定。
2.移除探针代码里冗余的参数,缩短参数名字的长度
另外一点,每台服务器的硬盘有限,带宽有限,如果参数名字太长,参数内容冗余,对服务器的硬盘和带宽都是一种极大的浪费。虽然每条日志都不起眼,但是日志起量了以后,就是会是一笔非常庞大的开销。
3.Nodejs + RabbitMq 搭建消息队列,缓解瞬间并发量
在 mac 上安装 RabbitMq
- 安装 HomeBrew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
- 使用 homeBrew 安装 RabbitMq
brew install rabbitmq
安装完成后
Management Plugin enabled by default at http://localhost:15672
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
To have launchd start rabbitmq now and restart at login:
brew services start rabbitmq
Or, if you don't want/need a background service you can just run:
rabbitmq-server
我们需要一个有效的登录名和密码,(默认用户名和密码都是guest)执行如下命令:
## 进入sbin目录
$ cd /usr/local/Cellar/rabbitmq/3.8.2/sbin
## 添加账号
$ ./rabbitmqctl add_user username password
## 设置超管权限
$ ./rabbitmqctl set_user_tags username administrator
## 添加访问权限
$ ./rabbitmqctl set_permissions -p / username ".*" ".*" ".*"
添加成功后访问:
消息服务启动了,那么如何存消息,如何取消息呢?如下图所示:

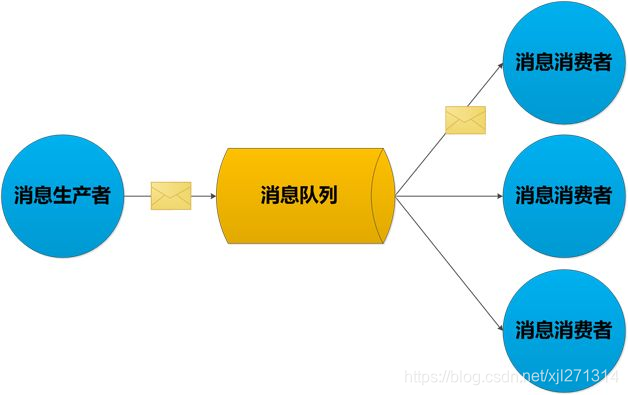
大致就是一个生产者和消费者的模式,生产者不停的向消息队列里生产消息,消费者在有需要的时候,从消息队列里取消息,一旦完成消费,队列里便移除这个消息。
消息的生产者和消费者互相没有感知,生产者产生过剩的消息都存放在消息队列里,由消费者慢慢消耗。以此来削峰填谷,达到处理高并发的目的。
let amqp = require("amqplib");
module.exports = class RabbitMQ {
constructor() {
this.hosts = ["amqp://localhost"];
this.index = 0;
this.length = this.hosts.length;
this.open = amqp.connect(this.hosts[this.index]);
}
// 消息生产者
sendQueueMsg(queueName, msg, errCallBack) {
let self = this;
self.open
.then(function(conn) {
return conn.createChannel();
})
.then(function(channel) {
return channel
.assertQueue(queueName)
.then(function(ok) {
return channel.sendToQueue(queueName, new Buffer.from(msg), {
persistent: true,
});
})
.then(function(data) {
if (data) {
errCallBack && errCallBack("success");
channel.close();
}
})
.catch(function() {
setTimeout(() => {
if (channel) {
channel.close();
}
}, 500);
});
})
.catch(function() {
// 这里尝试备用连接,我就一个,所以就处理了
});
}
// 消息消费者
receiveQueueMsg(queueName, receiveCallBack, errCallBack) {
let self = this;
self.open
.then(function(conn) {
return conn.createChannel();
})
.then(function(channel) {
return channel.assertQueue(queueName).then(function(ok) {
return channel
.consume(queueName, function(msg) {
if (msg !== null) {
let data = msg.content.toString();
channel.ack(msg);
receiveCallBack && receiveCallBack(data);
}
})
.finally(function() {});
});
})
.catch(function(e) {
errCallBack(e);
});
}
};
消息队列测试:每隔 5 秒发送一条消息,每隔 5 秒取出一条消息,成功
var mq = new RabbitMQ();
setInterval(function() {
mq.sendQueueMsg("queue1", "这是一个队列消息", function(err) {
console.log(err);
});
}, 5000);
setInterval(function() {
mq.receiveQueueMsg(
"queue1",
function(msg) {
console.log(msg);
},
function(error) {
console.log(error);
}
);
}, 5000);
TIP
RabbitMq 消息队列使用中遇到的坑:
var mq = new RabbitMQ()多次创建RabbitMQ对象,导致connections,channels,memory暴增,服务器很快挂掉。生产者的
channel忘记close, 导致channel太多,服务器超负荷。消费者的
channel被close掉了,永远只能接收到一条消息,消息队列很快爆掉。
接口耗时分析
我们前端用户感受到的却是接口总耗时,如果你不做前端接口的监控,那么你将无法得知用户真正的使用体验。
接口耗时分段分析
我将前端接口耗时划分为 5 个分段:<1 秒、1-5 秒、5-10 秒、10-30 秒、>30 秒
10 秒是用户可忍受等待时间的临界值,如果一个接口超过 10 秒还在 loading,用户极有可能杀掉程序。所以一般情况下,大于 10 秒的接口都可以认为是超时接口(特殊情况例外)。即使真的有这种情况,也应该让后端小伙伴把这个接口做成异步接口,在 10 秒内给用户一个反馈。
部分时候,我们最关心就是10-30秒这个段位,大部分超时的接口都会在这里发生。
单个接口分析
很多时候,出现接口问题的肯定某一个接口出现异常,如果是大面积异常,你的电话肯定被老板打爆了,也不需要监控了,哈哈。
那么针对单个接口我们应该分析哪些指标呢?
超时接口数量、单个接口的平均耗时、影响用户数量、发生页面个数、可以准确定位到某个小时和某一分钟发生的情况。
分析报警
分析报警可以分为多个指标:
超时接口数量、超时接口占比(百分比),影响用户数量。
其他文章
这里还有一篇采用录屏方式进行捕获的文章详细地址;
← 前端轻量自动化构建方案 前端代码规范 →